Pipelines that ask for help - Sending PagerDuty alerts from AzureDevops
For me, a pipeline is a sequential automation with a set of non-negotiable features. It’s not just about deploying new code; it’s about doing it in an automated and, above all, unattended manner. But here’s the crucial detail: for it to be truly unattended, you must be able to trust it.
Trusting doesn’t mean muttering “I did the best I could,” crossing your fingers, and side-eyeing it every time it runs, hoping it doesn’t fail. For me, trusting means that when something goes wrong —and it will— I’ll know instantly and will be able to take corrective action immediately. So, when we talk about automation, a non-negotiable feature is the ability to alert us to any unforeseen failures. This way, we don’t have to constantly look over our shoulders.
Lets see how!
Wake me, when you need me
In my work, most of our CI/CD automations are on Azure DevOps and our paging system is PagerDuty. So, if I want to avoid constantly monitoring our automations and only get notified when something fails or the execution doesn’t complete, the obvious solution is to combine both tools. This way, an error in the ADO pipelines will trigger a PagerDuty alert.
If you’ve had the need to send a PagerDuty alert from Azure DevOps and were surprised by the lack of documentation, my implementation example might interest you.
Ansible - Launch a PagerDuty Alert
Since I work a lot with Ansible, my preference is for the Azure Devops pipeline to run an Ansible job responsible for triggering the page. The first thing I did, of course, was try not to reinvent the wheel and find a PagerDuty alert module in the Ansible Community documentation.
Disclaimer: What follows is my opinion on this module. If you liked it or found it useful, that’s great.
At first, I tried using the module but given its unclear documentation, ambiguous parameter names, and —after looking a bit into its implementation— unnecessarily complex API calls, I opted for a simple solution that would cover my use case: I’m going to send a request to the PagerDuty API to generate an alert.
So, I set out to create a playbook that simply triggers a PD when you invoke it. Of course, it’s parameterizable.
---
- hosts: all
gather_facts: false
tasks:
- name: Fire up a PD alert (URI version)
ansible.builtin.uri:
url: https://api.pagerduty.com/incidents
method: POST
body_format: json
body:
incident:
type: incident
title: "Failure on Bounce pipeline execution for {{ env_name }}"
incident_key: ingincident_name
escalation_policy:
id: YTHGD
type: escalation_policy_reference
service:
id: YUUTYU
type: service_reference
return_content: true ## Being JSON, it will also be present in a json key in the dictionary of results
status_code: 201
headers:
Authorization: "Token token={{ pd_api_key }}"
Accept: "application/vnd.pagerduty+json;version=2"
delegate_to: localhost
run_once: true
We’re going to need a token, because the PagerDuty API won’t pay much attention to us without it. I take advantage of Ansible’s uri module, and by setting body_format as JSON, I can set the body: as a dictionary with the assurance that the module will convert it correctly. Let’s describe the interesting parameters in detail:
incident_key: it doesn’t need to be a unique value, but it should be descriptive.escalation_policy: we can easily find it by navigating to People->Escalation Policies in the PagerDuty portal, selecting the one we’re interested in, and then looking at the URL. The end of the URL will be something likeescalation_policies/YTHGD. That final value (YTHGD) is our escalation policy value.service: we obtain it in a similar way. We navigate to Services and extractservice-directory/YUUTYUfrom the URL, keeping the final value.Authorizationheader: it has a predefined format:"Token token=$tokenvalue"to indicate that we are going to send a token that we will generate beforehand. In the example, it references an Ansible variable defined in another file (encrypted, of course!).delegate_to: we are going to delegate execution of this task to the machine that is running the Ansible playbook, and not to the hosts we have in our inventory, thats why we specifylocalhostrun_once: we are setting this to true so this task only runs once, no matter how many hosts we have in our inventory.
The task is very straightforward and leverages a solid standard module. The last two parameters are to make sure of one thing and just one: We don´t wnat 40 PagerDuty alerts for a single pipeline that has failed and was set to run on 40 servers.
We now have our Ansible ready to trigger an alert when called, we just need that our pipeline knows when and how to call it.
Azure DevOps - Call the alert job if something is not right
ADO pipelines are defined in .yaml. All we need is a condition that in natural language reads “If any stage fails, the last stage that triggers an alert must execute”. And here is when we find something interesting and funny about Azure DevOps: This final stage must have a dependency with ALL other stages, because ADO only checks in its failed() if between both stages there´s a direct dependency relation. We cannot establish transitive dependencies here. Lets see with the example:
- stage: Trigger_PD_on_fail
displayName: "Trigger a PD alert if any previous step in the pipeline has failed"
dependsOn:
- Setup_stage
- Prepare_stage3
- Stage3
- Final_stage
condition: failed()
jobs:
- job: Trigger_PD_on_error
displayName: "Error detected, triggering PD alert"
pool:
vmImage: ubuntu-22.04
steps:
- checkout: none
- template: myplaybooks/ansible-fire-pd.yml
The stages defined in dependsOn are mere placeholders. With this, we can be sure the stage will only execute when any of the others it depends on (remember, must be all of them) does not execute correctly. Let´s see a few example runs:
Example
In this first one, all stages the alert depends on have ran correctly, nothing is triggered.
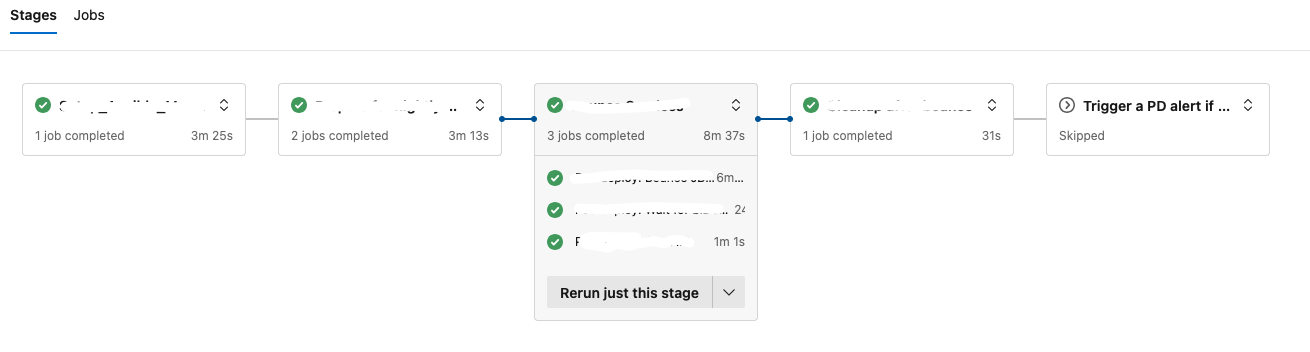
And, in the opossite, when one fails -or is manually cancelled- our alert triggers ready to pound our pager.
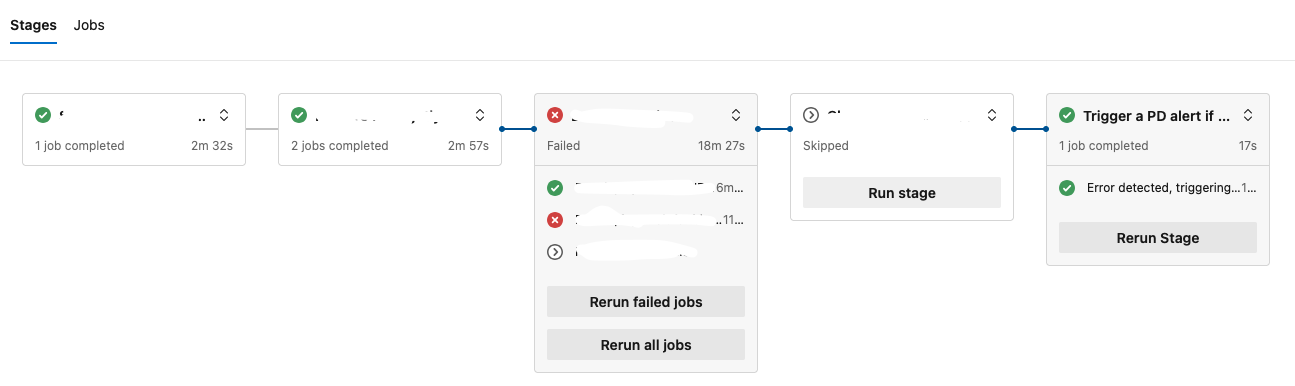
Conclusion
I was surprised to not find many examples of triggering a PagerDuty alert from Azure DevOps, as they are two widely used tools in SRE and DevOps.
Being able to trust our automations so they are truly unattended should be one of our main goals. To me, a good philosophy is to strive for reliability but be confident that we´ll get an alert when they aren´t. This way, we can be more than kinda confident. We can trust.