Pipelines que piden ayuda - Enviar alertas de PagerDuty desde AzureDevops
Una pipeline, para mí, es una automatización secuencial con una serie de características irrenunciables. No se trata solo de desplegar código nuevo, sino de hacerlo de manera automatizada y, sobre todo, desatendida. Pero aquí está el detalle crucial: para que sea verdaderamente desatendida, debes poder confiar en ella.
Confiar no significa decir “lo hice lo mejor que pude” cruzar los dedos y mirar de reojo cada vez que ejecuta esperando que no falle. Para mí, confiar significa que, cuando algo salga mal —y saldrá—, lo sabré al instante y podré tomar medidas correctivas de inmediato. Así que, si hablamos de automatización, una característica irrenunciable es la capacidad de alertarnos ante cualquier condición de fallo no prevista. De esta manera, no tendremos que estar vigilando constantemente las pipelines.
¡Vamos a ver cómo!
Despiértame, si me necesitas
Én mi trabajo, la mayoría de nuestras automatizaciones de CI/CD están en Azure DevOps y nuestro sistema de page es PagerDuty. Así que si quiero no estar pendiente de nuestras automation, y que me avisen sólo si algo falla o la ejecución no termina, lo evidente es combinar ambas herramientas para que un error en las pipelines de ADO envie una alerta de PagerDuty.
Si has tenido esta necesidad de enviar un PagerDuty desde Azure Devops y te ha sorprendido lo poco que hay documentado mi ejemplo de implementación podría interesarte.
Ansible - Lanza Alerta de PagerDuty
Como trabajo bastante con Ansible, mi preferncia es que la pipeline de Azure Devops ejecute un job de Ansible que sea el encargado de lanzar el page. Lo primero que hice, por supuesto, fue tratar de no re-inventar la rueda y encontrar un modulo de pagerduty alert en la documentación de Ansible Community.
Disclaimer: Lo que viene ahora es mi opinión sobre este módulo, si a ti te gustó o te sirve, maravilloso.
En un principio traté de utilizar el módulo pero al ver que tenía una documentación no demasiado clara, parametros con nombres ambigüos y -viendo un poco su implementación- unas llamadas a la API innecesariamente complejas, me decidí por la solución sencilla y que cubriera mi caso de uso: Voy a enviar un request a la API de PagerDuty para generar una alerta.
Así que me lancé a crear un playbook que simplemente lanza un PD si lo invocas. Parametrizable, claro.
---
- hosts: all
gather_facts: false
tasks:
- name: Fire up a PD alert (URI version)
ansible.builtin.uri:
url: https://api.pagerduty.com/incidents
method: POST
body_format: json
body:
incident:
type: incident
title: "Failure on Bounce pipeline execution for {{ env_name }}"
incident_key: ingincident_name
escalation_policy:
id: YTHGD
type: escalation_policy_reference
service:
id: YUUTYU
type: service_reference
return_content: true ## Being JSON, it will also be present in a json key in the dictionary of results
status_code: 201
headers:
Authorization: "Token token={{ pd_api_key }}"
Accept: "application/vnd.pagerduty+json;version=2"
delegate_to: localhost
run_once: true
Vamos a necesitar un token, porque la API de PagerDuty no nos va a hacer mucho caso si no. Aprovecho el módulo uri de ansible y al settear body_format como JSON puedo poner el body: como un diccionario con la tranquilidad de que el módulo va a convertirlo de manera correcta. Describamos en detalle los parámetros interesantes:
incident_key: no necesita ser un valor único, pero debería ser descriptivo.escalation_policy: podemos sacarla con facilidad desde el portal de PagerDuty navegando a People->EscalationPolicies, seleccionando la que nos interese y ahí, podemos fijarnos en la URL, el final será algo comoescalation_policies/YTHGDese valor final (YTHGD) es nuestro valor para la escalation policy.service: Lo obtenemos de manera similar. Navegamos a Services y de la URL sacamosservice-directory/YUUTYU, nos quedamos con el valor final.- Header de
Authorization: tiene un formato predefinido"Token token=$tokenvalue"para indicar que vamos a enviar un token que generaremos previamente. En el ejemplo, referencia una variable de ansible definida en otro archivo (¡Encriptado, claro!) delegate_to: vamos a delegar la ejecución de esta task a la máquina que corra el playbook de Ansible y no a los posibles hosts que tenga en el inventory, de ahí que pongamoslocalhost.run_once: vamos a settearlo a true para que esta task sólo corra una vez, independientemente del número de hosts que tengamos en el inventario.
La task es muy directa y aprovecha un módulo estándar sólido. Los dos últimos parámetros son para asegurarnos de una cosa y sólo de una cosa: No queremos 40 alertas de PagerDuty para una misma pipeline que ha fallado y tenía que correr sobre 40 servidores.
Ya tenemos nuestro Ansible preparado para alertarnos al ser llamado, ahora necesitamos que nuestra pipeline sepa cuándo y cómo debe llamarlo.
Azure DevOps - Llama al job de la alerta si algo no va bien
Las pipelines en ADO están definidas en .yaml. Todo lo que necesitamos es una definición con una condición que en lenguaje natural es “Si cualquier stage falla, que el stage final que lanza una alerta se ejecute”. Y aquí es cuándo nos encontramos con algo interesante y divertido de Azure DevOps: Este stage final que alerta debe depender de TODOS los demas, ya que ADO solo revisa el failed() si entre ambos stages hay una relación de dependencia. No podemos establecer relaciones transitivas de dependencia. Veamoslo con el ejemplo:
- stage: Trigger_PD_on_fail
displayName: "Trigger a PD alert if any previous step in the pipeline has failed"
dependsOn:
- Setup_stage
- Prepare_stage3
- Stage3
- Final_stage
condition: failed()
jobs:
- job: Trigger_PD_on_error
displayName: "Error detected, triggering PD alert"
pool:
vmImage: ubuntu-22.04
steps:
- checkout: none
- template: myplaybooks/ansible-fire-pd.yml
Los stages definidos en dependsOn son simples ejemplos placeholders. Con esto, ya nos hemos asegurado de que este stage se ejecute sólo cuándo alguno de los otros de los que depende (recordemos, deben ser todos los que queramos tener en cuenta) no se ejecute correctamente. Veamos un par de ejemplos de ejecución:
Ejemplo
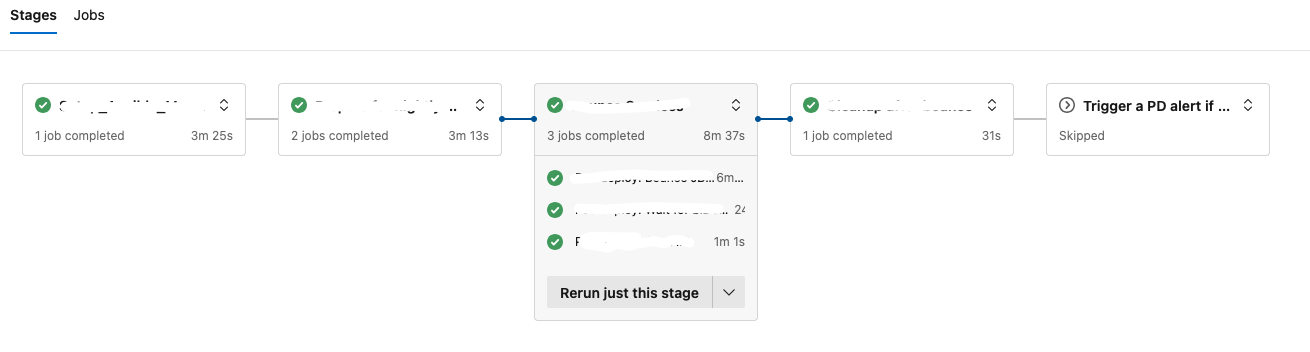
En el primer ejemplo, todos los stages de los que depende esta alerta ejecutan correctamente y no se lanza nada.
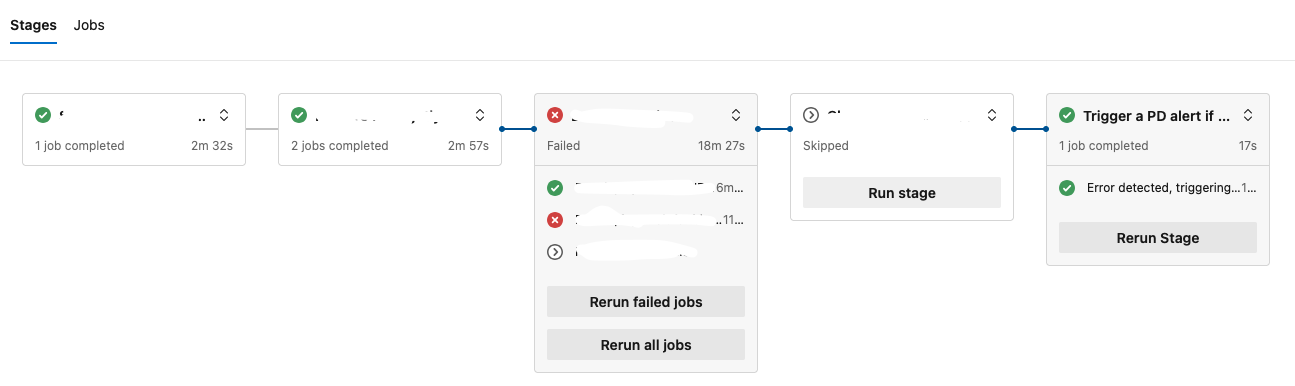
Y, de otro modo, cuando uno falla -o es cancelado a mano- nuestra alerta se dispara dispuesta a machacarnos el pager.
Conclusión
Me sorprendió no encontrar un montón de ejemplos de lanzar una alerta de PagerDuty desde Azure DevOps, ya que son dos herramientas muy utilizadas en el trabajo de SRE y DevOps.
Poder confiar en nuestras automatizaciones para que sean realmente desantendidas debería ser uno de nuestros objetivos principales. Para mí una buena filosofía es esforzarnos en que sean fiables pero estar seguros de que recibiremos una alerta cuando no lo sean, de esta manera podemos estar más que tranquilos. Podemos confiar.